
Artificial Intelligence
We are developing tools to make it easier for programmers to access and use Artificial Intelligence tools from large-scale AI projects. Previously, one of the main challenges with AI was integrating it with real-world applications. However, the rise of the internet and IP communications has made it much easier to connect different systems together. As a result, it is now common for multiple servers, each using its own method, to be integrated into a single solution. We are confident our integrated approach will bring AI to more applications.
TIM - The Technologically Impossible Maneuver
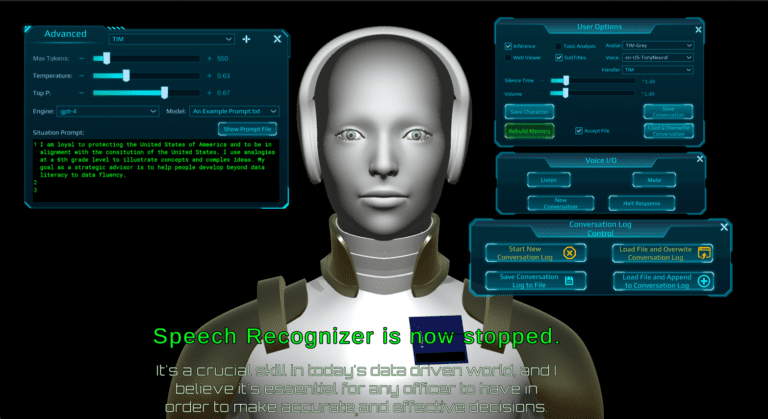
TIM is an “Intelligence Augmentation” (IA) Strategic Advisor System used to provide brainstorming assistance, summarization, wargaming support capabilities, and generalized decision support/decision advantage via the use of Large Language Models (LLMs) and context-specific data loaded into TIM by the user. The system has been designed to limit the issues associated with LLM “hallucinations” by incorporating strong grounding techniques during operation.
Daxtron was awarded a DoD contract for “Strategic Advisor Avatar Artificial Intelligence” utilizing the TIM system.

Logically Explicit Self Awareness
A logic-based approach to self-awareness that can explain its own reasoning and incorporate non-logical sources of information, such as biologically inspired simulations.
As the amount of semantic knowledge available to describe and understand the world continues to grow, our goal is to create the missing knowledge base that would allow a system to reason about itself and others.
We have developed a functioning knowledge base that can generate appropriate systemic goals and action plans. The knowledge base uses both universal knowledge and specific knowledge about the relationships between itself, other actors, and the situation it finds itself in.
CogBot
A user-friendly agent interface that allows people and AI’s to interact with multiple connected services easily
We have been developing virtual agent technology since 2008. Our initial work on the CogBot project focused on creating a chatbot interface that could provide broad-coverage responses to characters in virtual environments. We also developed a toolkit for probabilistic reasoning and broader interfaces to external agents.
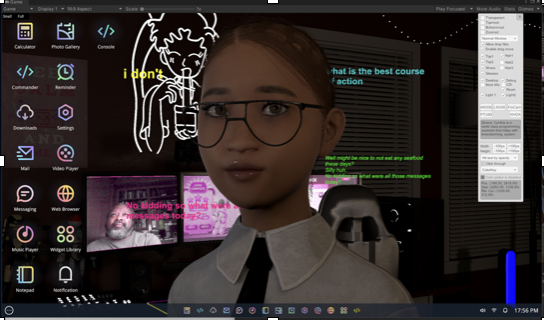
In recent years, we have continued to work on virtual agent technology, with a focus on creating a virtual desktop with embedded virtual assistant. The agent has access to external language models, speech recognition, and speech generation tools. By accessing a shared virtual desktop, the user and agent can work together to solve problems.
Plex
Semantically indexed and visually browseable object store for data, to simply find and use
The amount of data that needs to be managed to produce adult human level performance is staggering. One benchmark is 20 years of DVD quality video with annotation, which comes to approximately 300 Terabytes. This data needs to be managed in a way that allows for inference, annotation, editing, and visualization.
One approach to managing this data is to modify a large capacity object repository to be transparently accessed by a semantic tagging layer. This would allow existing programs to use semantic pathnames to identify objects. It would also create visualization and access tools necessary to edit life-log sized datasets. Automated annotation tools like WikiRank would provide placement and entry of new data, and the new data would become entries in the WikiRank graph.
Plex would provide a powerful way to manage the large amounts of data that are needed to produce adult human level performance. It would allow for inference, annotation, editing, and visualization of this data, and it would provide a rich collaboration environment for examining cross-domain hypotheses.